Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation
ICCV2025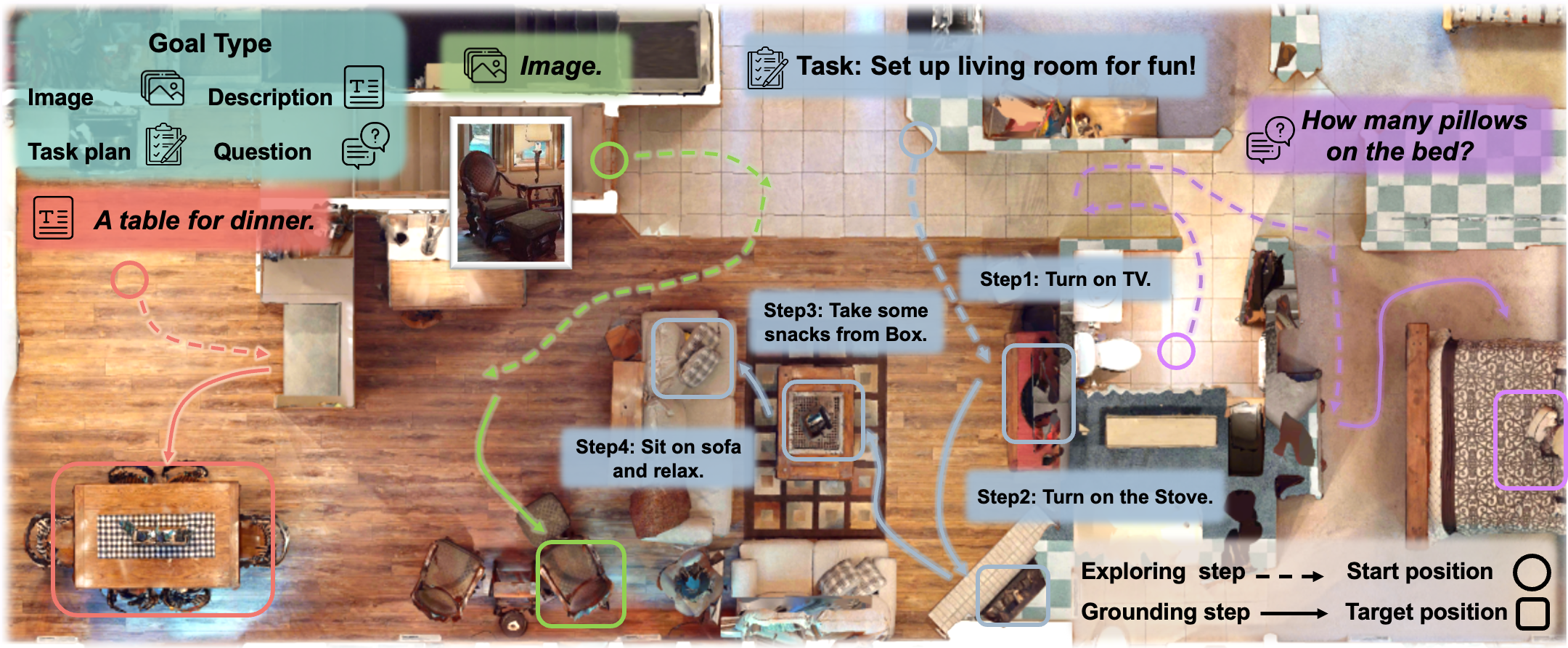
Abstract
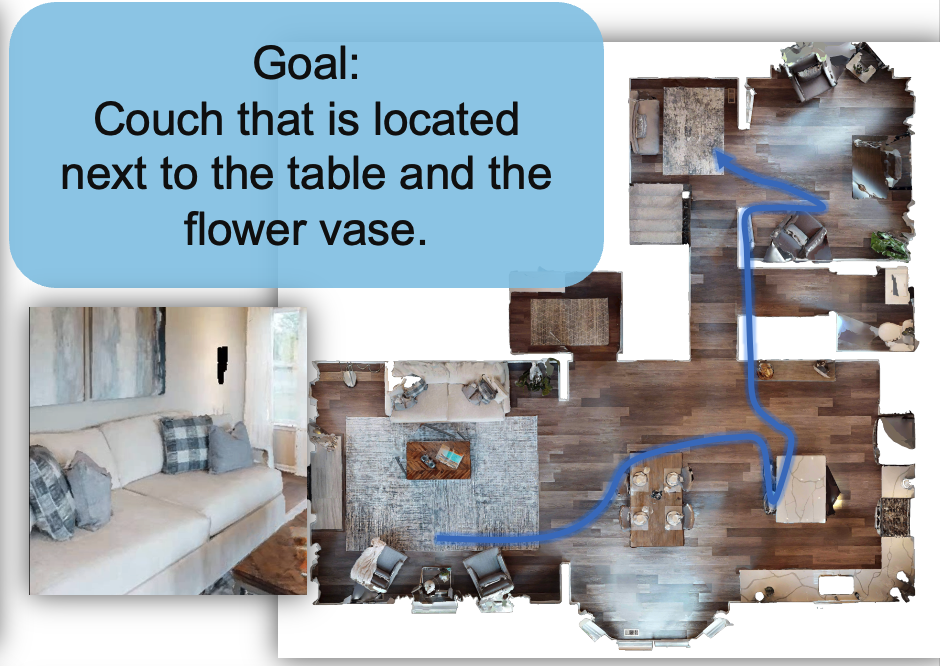
Embodied scene understanding requires not only comprehending visual-spatial information that has been observed but also determining where to explore next in the 3D physical world. Existing 3D Vision-Language (3D-VL) models primarily focus on grounding objects in static observations from 3D reconstruction, such as meshes and point clouds, but lack the ability to actively perceive and explore their environment. To address this limitation, we introduce Move to Understand (MTU3D), a unified framework that integrates active perception with 3D vision-language learning, enabling embodied agents to effectively explore and understand their environment. This is achieved by three key innovations: 1) Online query-based representation learning, enabling direct spatial memory construction from RGB-D frames, eliminating the need for explicit 3D reconstruction. 2) A unified objective for grounding and exploring, which represents unexplored locations as frontier queries and jointly optimizes object grounding and frontier selection. 3) End-to-end trajectory learning that combines Vision-Language-Exploration pre-training over a million diverse trajectories collected from both simulated and real-world RGB-D sequences. Extensive evaluations across various embodied navigation and question-answering benchmarks show that MTU3D outperforms state-of-the-art reinforcement learning and modular navigation approaches by 14%, 23%, 9%, and 2% in success rate on HM3D-OVON, GOAT-Bench, SG3D, and A-EQA, respectively. MTU3D's versatility enables navigation using diverse input modalities, including categories, language descriptions, and reference images. The deployment on a real robot demonstrates MTU3D's effectiveness in handling real-world data. These findings highlight the importance of bridging visual grounding and exploration for embodied intelligence.
Video
Contribution
- We present MTU3D, bridging visual grounding and exploration for efficient and versatile embodied navigation.
- We propose a unified objective that jointly optimizes grounding and exploration, leveraging their complementary nature to enhance overall performance.
- We propose a novel Vision-Language-Exploration training scheme, leveraging large-scale trajectories from simulation and real-world data.
- Extensive experiments validate the effectiveness of our approach, demonstrating significant improvements in exploration efficiency and grounding accuracy across open-vocabulary navigation, multi-modal lifelong navigation, task-oriented sequential navigation, and active embodied question-answering benchmarks.
Method

Quantitative results on HM3D-OVON
| Method | Val Seen | Val Seen Syn | Val Unseen | |||
|---|---|---|---|---|---|---|
| SR (↑) | SPL (↑) | SR (↑) | SPL (↑) | SR (↑) | SPL (↑) | |
| RL | 39.2 | 18.7 | 27.8 | 11.7 | 18.6 | 7.5 |
| DAgRL | 41.3 | 21.2 | 29.4 | 14.4 | 18.3 | 7.9 |
| VLFM | 35.2 | 18.6 | 32.4 | 17.3 | 35.2 | 19.6 |
| Uni-NaVid | 41.3 | 21.1 | 43.9 | 21.8 | 39.5 | 19.8 |
| TANGO | - | - | - | - | 35.5 | 19.5 |
| DAgRL+OD | 38.5 | 21.1 | 39.0 | 21.4 | 37.1 | 19.9 |
| Ours (MTU3D) | 55.0 | 23.6 | 45.0 | 14.7 | 40.8 | 12.1 |
Qualitative results from Simulator



Real-world robot deployment
Citation
@article{zhu2025mtu,
title = {Move to Understand a 3D Scene: Bridging Visual Grounding and Exploration for Efficient and Versatile Embodied Navigation},
author = {Zhu, Ziyu and Wang, Xilin and Li, Yixuan and Zhang, Zhuofan and Ma, Xiaojian and Chen, Yixin and Jia, Baoxiong and Liang, Wei and Yu, Qian and Deng, Zhidong and Huang, Siyuan and Li, Qing},
journal = {International Conference on Computer Vision (ICCV)},
year = {2025}
}
Relevant Projects


powered by Academic Project Page Template